泰坦尼克号乘客分析(Notebook)
这一小节中我们将会在 RussellCloud 上示范 kaggle 上面泰坦尼克号乘客死亡预测的例子。
您将在这个例子中学会:
- 如何上传数据集
- 如何添加依赖
- 如何创建 Jupyter 模式下的任务
目录:
准备:
- 注册RussellCloud账号
- 在本地安装 cli 客户端
- Clone 项目文件,Git地址
# clone代码 $ git clone https://github.com/RussellCLoud/kaggle_titanic - russell login 登录
# 使用russell login命令登录 $ russell login
数据集准备:
去网站登录,在控制台创建一个数据集,并使用下列命令初始化及上传数据集(准备数据集步骤可跳过,直接使用准备好的数据集,数据集ID:309252b75bb84eb89b01f47c3a1f78a5):
# 打开数据集所在目录
$ cd kaggle_titanic/data/
# 数据集初始化
$ russell data init --name Titanic_Predict
# 你也可以使用russell data init --id <数据集概览ID> 初始化
# 数据集上传
$ russell data upload
上传成功输出:
# 上传成功后你将会获得数据集的版本ID,非常重要,挂载只能使用版本ID
Upload finished
DATA ID NAME VERSION
-------------------------------- -------------------- -------
309252b75bb84eb89b01f47c3a1f78a5 Kaggle/Titanic_Predict:1 1
Upload finished, start extracting to data module
To check data status enter:
russell data status 309252b75bb84eb89b01f47c3a1f78a5
复现项目
新建项目
点击[项目创建页]创建名为Kaggle_Titanic的项目,默认环境选Keras。

初始化项目
# 转到 code 目录下
$ cd ../code
# 初始化项目
$ russell init --name Kaggle_Titanic
# 或使用russell init --id <项目概览ID>初始化
启动项目
本项目需要使用seaborn库进行数据可视化,我们将通过编写一个russell_requirements.txt文件来配置我们的依赖。然后通过 russell run 命令以 Jupyter 模式启动我们的项目。
# 创建russell_requirements.txt,配置seaborn库依赖
$ echo "seaborn" >> russell_requirements.txt
# 以jupyter模式启动,可能需要等待一小会,返回相应浏览器可访问的notebook链接
$ russell run --mode jupyter --data <data_id>:data
成功启动Jupyter:

结束任务
jupyter模式下的任务不会自动关闭,使用stop命令主动结束,如下:
# russell stop 关闭任务 <run_id>是运行成功后返回的标识ID
$ russell stop <run_id>
运行结果展示
运行中数据可视化:

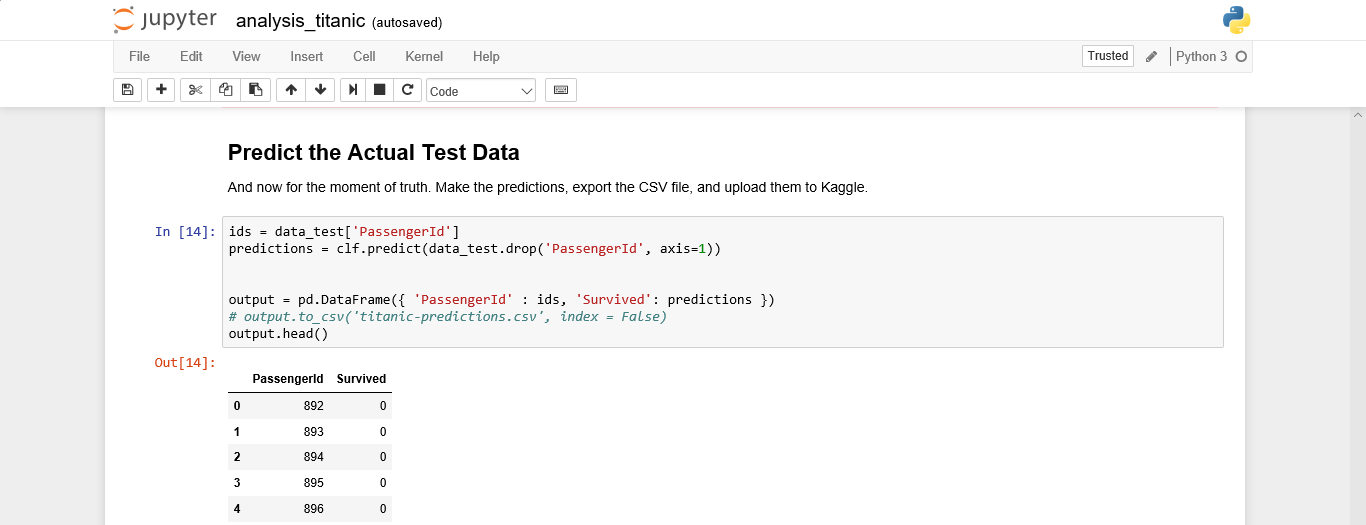
预测结果:
帮助我们完善文档
本文档同步公开在 GitHub 上。团队在尽力完善文档,但错误难免存在,或许有些功能迭代也未能及时更新在文档上。若你有什么新的想法或体验,欢迎提交 Pull Request 为我们提供支持。
除此之外,你还可以通过 issue 直接提交问题。